谷歌温州代理商-温州谷歌代理商-谷歌温州推广-温州谷歌推广-网站建设-小语种建站谷歌推广
联系人:邓先生
手机:086-15858758563
邮箱:621023874@qq.com
QQ:621023874
邮编:325000
在没有监督的情况下学习有用的表征仍然是机器学习中的关键挑战所在。在本文中,我们提出了一种简单但又强有力的生成模型,用以学习这样离散的表征方法。我们的模型,向量量化变分自动编码器(Vector Quantised-Variational AutoEncoder,VQ-VAE)与VAE在两个关键方面有所不同:编码器网络输出的是离散、而非连续的代码;而前一个是经过学习的、而非静止的。为了学习一种离散的潜表征,我们从向量量化(VQ)中提取了一些想法。使用VQ方法的好处是使得模型能够绕开“后崩溃(posterior collapse)”的问题,即当它们与一个强大的自回归解码器配对时,潜在问题都被忽略掉了,通常在VAE框架中可观察到这一现象。将这些表征与自回归先验相结合,则该模型可以生成高质量的图像、视频和语音,以及进行高质量的说话人声音转换(speaker conversion)和音素的无监督学习,从而为学习表征的实用性提供了进一步的证明。

最近,在图像、音频和视频的生成建模方面取得了一些令人印象深刻的样本和应用程序。同时,诸如少样本学习(few-shot learning)、域适应或强化学习等,这些具有挑战性的任务在很大程度上严重依赖于从原始数据中进行的学习表征,但是以一种无监督的方式进行训练的通用表征的有用性还远未成为一种占据主导地位的方法。
最大似然法(Maximum likelihood)和重构误差(reconstruction error)是用于在像素域中训练无监督模型的两个共同目标方法,然而它们的效用取决于特征应用的特定应用程序。我们的目标是实现一个模型,在其潜空间中保存数据的重要特征,同时优化最大似然法。正如我们的研究所表明的那样,最好的生成模型(以对数似然值(log-likelihood)度量)将是那些没有潜变量但功能强大的解码器(如PixelCNN)的生成模型。然而,在本文中,我们主张学习离散和有用的潜变量,即我们在各种领域中所展示的那样。
学习具有连续特征的学表征一直是许多以前研究所关注的重点,然而我们专注于离散表征,这可能与我们感兴趣的模式有一个潜在的吻合。语言本质上是离散的,类似地,语音通常被表示为一系列符号。图像通常可以用语言进行简洁地描述。此外,离散表征与复杂的推理、计划和预测性学习(例如,如果下雨,我将使用伞)也是非常的吻合的。虽然有证据证明,在深度学习中使用离散的潜变量是非常具有挑战性的,但是强大的自回归模型已经被开发出来,用于在离散变量的分布上建模。
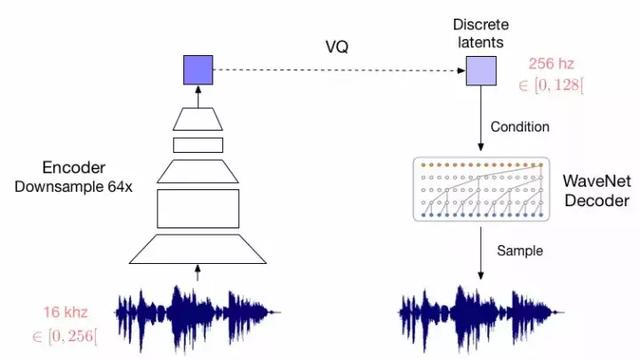
在我们的研究中,我们引入了一个新的生成模型,它们在给定一个观察方法的情况下,通过一个全新的(离散)潜在变量的后验分布的参数化,成功地将变分自动编码器(VAE)与离散的潜在表征方法结合在一起。我们的模型依赖于向量量化(VQ),且训练简单,受方差的影响较小,还避免了“后崩溃”问题,这是许多VAE模型所存在的问题,它们有一个强大的解码器,通常是由于潜变量被忽略引起的。此外,它是第一个离散的潜VAE模型,其性能与其连续的配对物相似,同时提供了离散分布的灵活性。我们把模型称为VQ-VAE,由于VQ-VAE可以有效地利用潜空间,因此它可以成功地对许多重要特征进行建模,而这些特征通常是跨越数据空间中的多个维度(例如,目标跨越图像中的多个像素、语音中的多个音素、文本片段中的多个信息等),而不是把注意力集中在噪音和不可察觉的细节上,而这些细节往往是局部的。
最后,一旦VQ-VAE发现了一种很好的离散潜结构,我们就对这些离散的随机变量进行强大的先验训练,产生有趣的样本和有用的应用。例如,在语言训练中,我们发现了语言的潜结构,并没有关于音素或单词的任何监督或先验知识。此外,我们可以为我们的解码器配备说话者标识,这使得说话人声音转换得以实现,即在不改变内容的情况下将语音从一个说话者迁移到另一位说话者。我们在学习强化学习的长期环境结构方面也取得了可喜的成果。
我们的贡献可以概括为:
?引入简单的VQ-VAE模型,使用离散潜伏性,不会遭受“后崩溃”,也没有变异问题。
?我们证明了离散潜模型(VQ-VAE)以及对数似然函数的连续模型。
?当与强大的先验配对时,我们的样本在诸如语音和视频生成等各种应用中是连贯和高质量的。
?我们展示了通过原始语音学习语言的证据,没有任何监督,并显示无监督的扬声器转换的应用。
结论
在这项工作中,我们已经介绍了VQ-VAE,这是一个将VAE和矢量量化相结合以获得离散的潜表示的新的模型家族。我们已经证明VQ-VAE能够通过压缩的离散潜空间建模长期的相关性,我们已经通过生成128×128彩色图像、取样动作条件视频序列以及最终使用音频来证明这一点,即使是无条件模型也可以生成令人惊讶的有意义的语言和说话人声音转换。所有这些实验都表明,VQ-VAE学习的离散潜空间以完全无监督的方式捕获数据的重要特征。此外,VQ-VAE在CIFAR10数据上实现的可能性几乎与它们连续潜变量相当。我们认为,这是第一个能够成功模拟长距离序列的离散潜变量模型,并且完全无监督地学习与音素密切相关的高级语音描述符。
神经离散表征学习
以下的所有样本均来自VQ-VAE,以一种非监督的方式从未对齐的数据中获得的。
重建
这些样本是来自VQ-VAE的重建,它将音频输入以64倍的规格压缩为离散潜代码中。VQ-VAE和潜空间都是经过端对端训练的,不依赖于音素或波形本身以外的信息。虽然重建的波形与原始的形状非常不同,但听起来非常相似。